验证码-自定义数据集与定长图文识别
目录
前言
TIP
- 自定义数据集
- 定长图文识别 (包含字符: 数字+小写字母+大写字母 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ)
卷积神经网络(Convolutional Neural Network, CNN)是深度学习中专门用于处理图像、视频等网格结构数据的神经网络模型。
它通过模仿人类视觉系统的处理方式,能够自动从原始数据中提取特征并进行分类识别,在计算机视觉领域取得了革命性的突破。
一、实现数据加载起
py
import os
import string
from pathlib import Path
from PIL import Image
from torch.utils.data import Dataset
class LetterDataset(Dataset):
def __init__(self, root: str = "./picture", transform=None):
self.path = root
self.transform = transform
self.images = self._load_picture_path()
self.mapper = [i for i in string.ascii_lowercase[0:8]]
print(self.images)
def _load_picture_path(self):
# 使用 lambda 表达式过滤图片文件
image_extensions = {'.jpg', '.jpeg', '.png', '.gif', '.bmp', '.tiff', '.webp'}
# 使用 os.walk 和 lambda 表达式获取所有图片路径
picture_paths = list(
map(lambda walk_result: [
[file, Path(walk_result[0]) / file]
for file in walk_result[2]
if os.path.splitext(file)[1].lower() in image_extensions
], os.walk(self.path))
)
# 将嵌套列表展平
picture_paths = [item for sublist in picture_paths for item in sublist]
return picture_paths
def __getitem__(self, index):
image = self.images[index]
labels = [self.mapper.index(i) for i in image[0].split('_')[0]]
image_path = image[1]
pic = Image.open(image_path)
if self.transform:
pic = self.transform(pic)
return pic, labels
def __len__(self):
return len(self.images)
if __name__ == '__main__':
from torchvision import transforms
transforms = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize(mean=[0.1307, ], std=[0.3081, ]),
]
)
dataset = LetterDataset(transform=transforms)
print(dataset[0])
# print(dataset._load_picture_path()[0][-1])py
import os
import string
from pathlib import Path
from PIL import Image
from torch.utils.data import Dataset
class LetterDataset(Dataset):
def __init__(self, root: str = "./picture", transform=None):
self.path = root
self.transform = transform
self.images = self._load_picture_path()
self.mapper = [i for i in string.ascii_lowercase[0:8]]
print(self.images)
def _load_picture_path(self):
# 使用 lambda 表达式过滤图片文件
image_extensions = {'.jpg', '.jpeg', '.png', '.gif', '.bmp', '.tiff', '.webp'}
# 使用 os.walk 和 lambda 表达式获取所有图片路径
picture_paths = list(
map(lambda walk_result: [
[file, Path(walk_result[0]) / file]
for file in walk_result[2]
if os.path.splitext(file)[1].lower() in image_extensions
], os.walk(self.path))
)
# 将嵌套列表展平
picture_paths = [item for sublist in picture_paths for item in sublist]
return picture_paths
def __getitem__(self, index):
image = self.images[index]
labels = [self.mapper.index(i) for i in image[0].split('_')[0]]
image_path = image[1]
pic = Image.open(image_path)
if self.transform:
pic = self.transform(pic)
return pic, labels
def __len__(self):
return len(self.images)
if __name__ == '__main__':
from torchvision import transforms
transforms = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize(mean=[0.1307, ], std=[0.3081, ]),
]
)
dataset = LetterDataset(transform=transforms)
print(dataset[0])
# print(dataset._load_picture_path()[0][-1])二、计算标准值
MyDataset 下的compute_mean_std 来计算后需要用的 mean & std
py
import os
import string
from pathlib import Path
import torch
from PIL import Image
from torch.utils.data import Dataset
class LetterDataset(Dataset):
def __init__(self, root: str = "./picture/train/", transform=None):
self.path = root
self.transform = transform
self.images = self._load_picture_path()
CHAR_SET = string.digits + string.ascii_lowercase + string.ascii_uppercase
self.mapper = [i for i in CHAR_SET]
def _load_picture_path(self):
# 使用 lambda 表达式过滤图片文件
image_extensions = {'.jpg', '.jpeg', '.png', '.gif', '.bmp', '.tiff', '.webp'}
# 使用 os.walk 和 lambda 表达式获取所有图片路径
picture_paths = list(
map(lambda walk_result: [
[file, Path(walk_result[0]) / file]
for file in walk_result[2]
if os.path.splitext(file)[1].lower() in image_extensions
], os.walk(self.path))
)
# 将嵌套列表展平
picture_paths = [item for sublist in picture_paths for item in sublist]
return picture_paths
def __getitem__(self, index):
image = self.images[index]
labels = [self.mapper.index(i) for i in image[0].split('_')[0]]
image_path = image[1]
pic = Image.open(image_path)
if self.transform:
pic = self.transform(pic)
labels = torch.as_tensor(labels, dtype=torch.int64)
return pic, labels
def __len__(self):
return len(self.images)
def compute_mean_std(dataset):
"""
计算数据集的均值和标准差
:param dataset: LetterDataset实例
:return: (mean, std)
"""
# 创建只包含ToTensor转换的数据加载器
from torch.utils.data import DataLoader
# 临时transform,只做ToTensor,不包含Normalize
temp_transform = transforms.Compose([transforms.ToTensor()])
dataset.transform = temp_transform
dataloader = DataLoader(dataset, batch_size=1, shuffle=False, num_workers=0)
mean = torch.zeros(3)
std = torch.zeros(3)
total_images = len(dataset)
print(f'开始计算{total_images}张图像的均值和标准差...')
for images, labels in dataloader:
for d in range(3): # 对RGB三个通道分别计算
mean[d] += images[:, d, :, :].mean()
std[d] += images[:, d, :, :].std()
mean /= total_images
std /= total_images
return mean.tolist(), std.tolist()
# 使用示例
if __name__ == '__main__':
from torchvision import transforms
# 先计算均值和标准差
dataset = LetterDataset(transform=None) # 初始不包含transform
mean, std = compute_mean_std(dataset)
print(f'计算完成 - Mean: {mean}, Std: {std}')
# 然后使用计算出的值创建最终的transform
final_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=mean, std=std),
])
# 重新初始化数据集使用正确的Normalize参数
dataset = LetterDataset(transform=final_transform)结果:
三、训练 & 测试
3.1 生成数据
数量
- 训练集 ./picture/train 50_000张
- 测试集 ./picture/test 2_000张
尺寸
4个字符(数字+大小写字母) 150*50
干扰
- 划线
- 噪点
命名
验证码_时间戳.png
效果


3.2 完整代码
py
from PIL import Image, ImageDraw, ImageFont
import random
import time
import cv2
import numpy as np
import os
def generate_captcha_custom(batch_size=1, save_images=False, save_path="./captcha_images/", is_name=True):
"""
完全自定义的验证码生成函数,支持彩色噪点
"""
WIDTH = 150
HEIGHT = 50
CHAR_SET = '0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'
CAPTCHA_LEN = 4
images = []
labels = []
file_paths = []
if save_images:
os.makedirs(save_path, exist_ok=True)
for i in range(batch_size):
# 随机生成文本
text = ''.join(random.choices(CHAR_SET, k=CAPTCHA_LEN))
# 创建白色背景图片
image = Image.new('RGB', (WIDTH, HEIGHT), color=(255, 255, 255))
draw = ImageDraw.Draw(image)
# 加载字体(黑色)
try:
font = ImageFont.truetype("arial.ttf", 11) # 字体大小32
except:
font = ImageFont.load_default()
# 计算文本尺寸和位置(居中)
text_width = draw.textlength(text, font=font)
text_height = 32 # 字体大小
# 计算字母间距(每个字符间隔)
char_spacing = 5 # 字母间距像素
total_width = text_width + (len(text) - 1) * char_spacing
start_x = (WIDTH - total_width) // 2
start_y = (HEIGHT - text_height) // 2
# 逐个绘制字符(控制间距)
for j, char in enumerate(text):
char_x = start_x + j * (text_width / len(text) + char_spacing)
char_y = start_y + random.randint(-3, 3) # 轻微垂直随机偏移
draw.text((char_x, char_y), char, font=font, fill=(0, 0, 0)) # 黑色字体
# ==================== 添加彩色噪点 ====================
def add_color_noise(draw_obj, width, height, noise_density=0.01):
"""
添加彩色噪点到图片
noise_density: 噪点密度,建议0.01-0.05
"""
total_pixels = width * height
num_noise = int(total_pixels * noise_density)
for _ in range(num_noise):
x = random.randint(0, width - 1)
y = random.randint(0, height - 1)
# 生成随机RGB颜色
noise_color = (
random.randint(0, 255), # R
random.randint(0, 255), # G
random.randint(0, 255) # B
)
draw_obj.point((x, y), fill=noise_color)
def add_salt_pepper_noise(draw_obj, width, height, salt_prob=0.01, pepper_prob=0.01):
"""
添加椒盐噪点(黑白噪点)
"""
total_pixels = width * height
num_salt = int(total_pixels * salt_prob)
num_pepper = int(total_pixels * pepper_prob)
# 添加盐噪声(白点)
for _ in range(num_salt):
x = random.randint(0, width - 1)
y = random.randint(0, height - 1)
draw_obj.point((x, y), fill=(255, 255, 255))
# 添加椒噪声(黑点)
for _ in range(num_pepper):
x = random.randint(0, width - 1)
y = random.randint(0, height - 1)
draw_obj.point((x, y), fill=(0, 0, 0))
# 应用彩色噪点
add_color_noise(draw, WIDTH, HEIGHT, noise_density=0.02)
# 可选:添加椒盐噪点增加干扰
add_salt_pepper_noise(draw, WIDTH, HEIGHT, salt_prob=0.005, pepper_prob=0.005)
# ==================== 噪点添加结束 ====================
# 添加干扰线(保持原有)
for _ in range(4):
x1 = random.randint(0, WIDTH)
y1 = random.randint(0, HEIGHT)
x2 = random.randint(0, WIDTH)
y2 = random.randint(0, HEIGHT)
# 干扰线也使用随机颜色
line_color = (
random.randint(50, 200),
random.randint(50, 200),
random.randint(50, 200)
)
draw.line([(x1, y1), (x2, y2)], fill=line_color, width=1)
if save_images:
timestamp = str(int(time.time() * 1000)) + f"_{i}"
if is_name:
filename = f"{text}_{timestamp}.png"
else:
filename = "test.png"
full_path = os.path.join(save_path, filename)
image.save(full_path)
file_paths.append(full_path)
print(f"已保存: {full_path}")
# 转为灰度图并归一化
image_array = cv2.cvtColor(np.array(image), cv2.COLOR_RGB2GRAY)
image_array = image_array / 255.0
images.append(image_array)
labels.append(text)
return np.array(images), labels, file_paths
# 使用示例
if __name__ == "__main__":
# 生成5个带彩色噪点的验证码
# images, labels, paths = generate_captcha_custom(
# batch_size=50000,
# save_images=True,
# save_path="./picture/train",
# )
# images, labels, paths = generate_captcha_custom(
# batch_size=2000,
# save_images=True,
# save_path="./picture/test",
# )
images, labels, paths = generate_captcha_custom(
batch_size=1,
save_images=True,
save_path="./",
)
print(f"生成验证码标签: {labels}")py
# 模型
from torch import nn
from torchvision import models
# 字符分类数量 数字+大小写字母
cate = 62
class AnlanNetModel(nn.Module):
def __init__(self):
super(AnlanNetModel, self).__init__()
self.resnet18 = models.resnet18(num_classes=4 * cate)
def forward(self, x):
x = self.resnet18(x)
return xpy
import os
import string
from pathlib import Path
import torch
from PIL import Image
from torch.utils.data import Dataset
class LetterDataset(Dataset):
def __init__(self, root: str = "./picture/train/", transform=None):
self.path = root
self.transform = transform
self.images = self._load_picture_path()
CHAR_SET = string.digits + string.ascii_lowercase + string.ascii_uppercase
self.mapper = [i for i in CHAR_SET]
def _load_picture_path(self):
# 使用 lambda 表达式过滤图片文件
image_extensions = {'.jpg', '.jpeg', '.png', '.gif', '.bmp', '.tiff', '.webp'}
# 使用 os.walk 和 lambda 表达式获取所有图片路径
picture_paths = list(
map(lambda walk_result: [
[file, Path(walk_result[0]) / file]
for file in walk_result[2]
if os.path.splitext(file)[1].lower() in image_extensions
], os.walk(self.path))
)
# 将嵌套列表展平
picture_paths = [item for sublist in picture_paths for item in sublist]
return picture_paths
def __getitem__(self, index):
image = self.images[index]
labels = [self.mapper.index(i) for i in image[0].split('_')[0]]
image_path = image[1]
pic = Image.open(image_path)
if self.transform:
pic = self.transform(pic)
labels = torch.as_tensor(labels, dtype=torch.int64)
return pic, labels
def __len__(self):
return len(self.images)
def compute_mean_std(dataset):
"""
计算数据集的均值和标准差
:param dataset: LetterDataset实例
:return: (mean, std)
"""
# 创建只包含ToTensor转换的数据加载器
from torch.utils.data import DataLoader
# 临时transform,只做ToTensor,不包含Normalize
temp_transform = transforms.Compose([transforms.ToTensor()])
dataset.transform = temp_transform
dataloader = DataLoader(dataset, batch_size=1, shuffle=False, num_workers=0)
mean = torch.zeros(3)
std = torch.zeros(3)
total_images = len(dataset)
print(f'开始计算{total_images}张图像的均值和标准差...')
for images, labels in dataloader:
for d in range(3): # 对RGB三个通道分别计算
mean[d] += images[:, d, :, :].mean()
std[d] += images[:, d, :, :].std()
mean /= total_images
std /= total_images
return mean.tolist(), std.tolist()
# 使用示例
if __name__ == '__main__':
from torchvision import transforms
# 先计算均值和标准差
dataset = LetterDataset(transform=None) # 初始不包含transform
mean, std = compute_mean_std(dataset)
print(f'计算完成 - Mean: {mean}, Std: {std}')
# 然后使用计算出的值创建最终的transform
final_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=mean, std=std),
])
# 重新初始化数据集使用正确的Normalize参数
dataset = LetterDataset(transform=final_transform)
# if __name__ == '__main__':
# from torchvision import transforms
# transforms = transforms.Compose(
# [
# transforms.ToTensor(),
# transforms.Normalize(mean=[0.1307, ], std=[0.3081, ]),
# ]
# )
# dataset = LetterDataset(transform=transforms)
# transform = transforms.Compose([transforms.ToTensor()])
# dataset = LetterDataset(transform=transform)
# mean, std = compute_mean_std(dataset)
# print(f'Mean: {mean}, Std: {std}')py
import torch
from torch import save
from torchvision import transforms
from torch.utils.data import DataLoader
from torch import nn, optim
from tqdm import tqdm
import test
import numpy as np
from MyDataset import LetterDataset
from MyModels import AnlanNetModel
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 模型
batch_size = 8
cate = 62
# 实例化模型
model = AnlanNetModel()
optimizer = optim.Adam(model.parameters())
# 加载以及训练好的模型和优化器继续训练
model = model.to(device)
loss_fn = nn.CrossEntropyLoss()
# transforms.Normalize(mean=[0.94326925, 0.94316506, 0.9447249], std=[0.19776213, 0.197599402, 0.19384143]),
transforms = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize(mean= [0.9629541635513306, 0.9628686308860779, 0.9629123210906982], std=[0.1542653739452362, 0.15452951192855835, 0.154421865940094]),
]
)
mine_train = LetterDataset(root='./picture/train/', transform=transforms)
def train(epoch):
total_loss = []
data_loader = DataLoader(mine_train, batch_size=batch_size, shuffle=True,drop_last=True)
data_loader = tqdm(data_loader, total=len(data_loader))
model.train()
# 三件套
for (img, label) in data_loader:
img = img.to(device)
label = label.to(device)
# 梯度置0
optimizer.zero_grad()
# 传播
output = model(img)
output = output.view(batch_size * 4, cate)
label = label.view(-1)
# 单次优化
loss = loss_fn(output, label)
total_loss.append(loss.item())
data_loader.set_description("loss: %.4f" % np.mean(total_loss))
# 反向传播
loss.backward()
# 优化器更新
optimizer.step()
save(model.state_dict(), './models/model.pkl')
save(optimizer.state_dict(), './models/optimizer.pkl')
loss = np.mean(total_loss)
print(f"\n第{epoch}轮epoch, 损失为:\t{loss} ", )
print("=====================================================================")
for i in range(10):
epoch = i + 1
train(epoch)
print(f"\n第{epoch}轮epoch, 成功率:\t {test.test_success(i)}")py
import os
import torch
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader
from torch import nn
from tqdm import tqdm
import numpy as np
from MyDataset import LetterDataset
from MyModels import AnlanNetModel
batch_size = 8
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
cate = 62
def test_success(t):
# 实例化模型
model = AnlanNetModel()
model = model.to(device)
loss_fn = nn.CrossEntropyLoss()
if os.path.exists('./models/model.pkl'):
model.load_state_dict(torch.load('./models/model.pkl'))
from torchvision import transforms
transforms = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize(mean=[0.9629541635513306, 0.9628686308860779, 0.9629123210906982],
std=[0.1542653739452362, 0.15452951192855835, 0.154421865940094]),
]
)
mine_train = LetterDataset(root='./picture/test/', transform=transforms)
data_loader = DataLoader(mine_train, batch_size=batch_size, shuffle=True,drop_last=True)
data_loader = tqdm(data_loader, total=len(data_loader))
model.eval()
# 成功率列表
succeed = []
total_loss = []
total_acc = []
# 三件套
with torch.no_grad():
for (img, label) in data_loader:
img = img.to(device)
label = label.to(device)
# 获取结果
output = model(img)
output = output.view(batch_size * 4, cate)
label = label.view(-1)
loss = loss_fn(output, label)
total_loss.append(loss.item())
pred = output.max(dim=1)[1]
result = output.max(dim=1).indices
succeed.append(result.eq(label).float().mean().item())
# 单次优化
total_acc.append(pred.eq(label).float().mean().item())
return np.mean(total_acc)
# print(test_success(1))注意
第二步的 计算标准值 就是在这用 transforms.Normalize(mean= [0.9629541635513306, 0.9628686308860779, 0.9629123210906982], std=[0.1542653739452362, 0.15452951192855835, 0.154421865940094]),
3.3 训练
这种字体较小的,数据集太小效果会很不理想,大概只有20% (自测)
本项目数据集在5万, 正确率在96%以上 😊
初始正确率
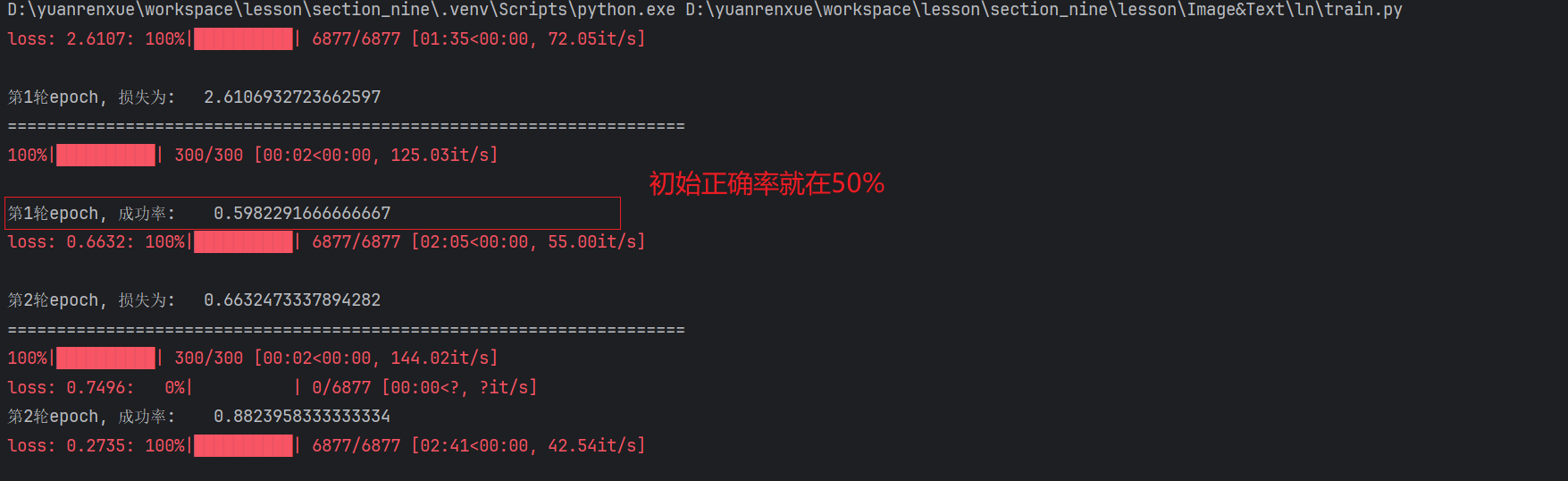
最终正确率
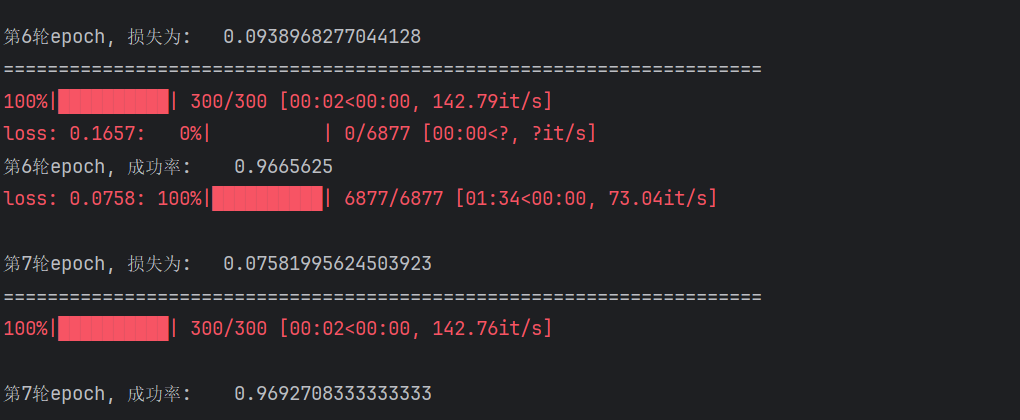
四、推理
py
import os
import requests
import torch
import numpy as np
from MyDataset import LetterDataset
from MyModels import AnlanNetModel
from PIL import Image
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def infer_success(path):
# 实例化模型
model = AnlanNetModel()
if os.path.exists('./models/model.pkl'):
model.load_state_dict(torch.load('./models/model.pkl'))
from torchvision import transforms
transforms = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize(mean=[0.9629541635513306, 0.9628686308860779, 0.9629123210906982],
std=[0.1542653739452362, 0.15452951192855835, 0.154421865940094]),
]
)
dataset = LetterDataset(transform=transforms)
mapper = dataset.mapper
model.eval()
# 三件套
with torch.no_grad():
# 加载图像并预处理
# 从URL加载图像[6,7,8](@ref)
img_url = 'http://spiderdemo.cn/captcha/api/cap1_challenge/captcha_image/?t=1767325995410'
# 添加浏览器头信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}
# 发送GET请求获取图片[5,6](@ref)
response = requests.get(img_url, headers=headers, stream=True)
response.raise_for_status() # 检查请求是否成功
with open("./test.png", 'wb') as f:
f.write(response.content)
f.close()
# img = Image.open("./test.png")
img = Image.open(path)
img = transforms(img) # 转换为Tensor
# 关键修复:将输入数据移动到与模型相同的设备[1,4](@ref)
# 添加batch维度
img = img.unsqueeze(0) # [C, H, W] -> [1, C, H, W]
# 获取结果
output = model(img)
output = output.view(4, 62)
pred = output.max(dim=1)[1]
captcha = "".join([mapper[i] for i in list(pred.numpy())])
if captcha == path.replace('./',"").split('_')[0]:
print("✅ 识别到的验证码: ", captcha)
else:
print("❌ 识别到的验证码: ", captcha)
infer_success('./test.png')
infer_success('./WwBD_1767334918159_0.png')
infer_success('./WVWd_1767334988473_0.png')
infer_success('./Thjz_1767336932085_0.png')
infer_success('./xhvZ_1767337579945_0.png')推理图片

test.png

WwBD_1767334918159_0.png

WVWd_1767334988473_0.png

Thjz_1767336932085_0.png

xhvZ_1767337579945_0.png
注意:
- 第一张和第二张都是其他网站的验证码,效果很不理想
- 后三张全是根据source_code生成后,效果非常好
效果
