猿人学-验证码-T18不定长验证码之验证码计算
目录
前言
TIP
不定长验证码识别
- 模型: ResNet + LSTM
- 数据集:
- train: 20000
- test: 2000
- 成功率: 99%
一、图片展示




二、思路
核心步骤:
- 计算标准值
- 训练模型
- 推理
- 计算验证码
- 请求数据
三、计算标准值
py
def compute_mean_std_pytorch(dataset, batch_size=8):
"""
使用PyTorch张量高效计算数据集的均值和标准差
"""
import torch
from torchvision import transforms as T # 重命名避免冲突
from tqdm import tqdm
original_transform = dataset.transform
dataset.transform = None
print("使用PyTorch方法计算...")
# 初始化统计变量
mean_accum = 0.0
sq_mean_accum = 0.0
num_pixels = 0
for i in tqdm(range(0, len(dataset), batch_size)):
batch_indices = range(i, min(i + batch_size, len(dataset)))
batch_pixels = []
for idx in batch_indices:
pic, labels, length = dataset[idx]
# 使用明确的模块引用
if isinstance(pic, Image.Image):
img_tensor = T.ToTensor()(pic) # 使用 T 而不是 transforms
else:
img_tensor = pic if torch.is_tensor(pic) else torch.tensor(pic)
batch_pixels.append(img_tensor)
if batch_pixels:
batch_tensor = torch.stack(batch_pixels)
batch_pixels_count = batch_tensor.numel()
# 累加统计量
pixel_sum = batch_tensor.sum()
pixel_sq_sum = (batch_tensor ** 2).sum()
# 更新全局统计(使用加权平均)
batch_mean = pixel_sum / batch_pixels_count
batch_sq_mean = pixel_sq_sum / batch_pixels_count
mean_accum = (num_pixels * mean_accum + batch_pixels_count * batch_mean) / (num_pixels + batch_pixels_count)
sq_mean_accum = (num_pixels * sq_mean_accum + batch_pixels_count * batch_sq_mean) / (
num_pixels + batch_pixels_count)
num_pixels += batch_pixels_count
# 计算最终标准差:sqrt(E[X²] - (E[X])²)
final_std = torch.sqrt(sq_mean_accum - mean_accum ** 2)
dataset.transform = original_transform
return [mean_accum.item()] * 3, [final_std.item()] * 3
if __name__ == '__main__':
from torchvision import transforms
transforms = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize(mean=[0.1307, ], std=[0.3081, ]),
]
)
dataset = LetterDataset(transform=transforms)
#
# # 2. 计算数据集的均值和标准差
# mean, std = compute_mean_std_pytorch(dataset, batch_size=32)
#
# # 3. 打印结果,并用于创建新的、包含标准化的数据加载流程
# print(f"计算得到的均值: {mean}")
# print(f"计算得到的标准差: {std}")四、训练模型
完整代码
py
import torch
import torch.nn as nn
from torch.nn import functional as F
cate = 17
class RestNetBasicBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride):
super(RestNetBasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=stride, padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self, x):
output = self.conv1(x)
output = F.relu(self.bn1(output))
output = self.conv2(output)
output = self.bn2(output)
return F.relu(x + output)
class RestNetDownBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride):
super(RestNetDownBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride[0], padding=1)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=stride[1], padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)
self.extra = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride[0], padding=0),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
extra_x = self.extra(x)
output = self.conv1(x)
out = F.relu(self.bn1(output))
out = self.conv2(out)
out = self.bn2(out)
return F.relu(extra_x + out)
class ResNet_LSTM_Shape(nn.Module):
def __init__(self):
super(ResNet_LSTM_Shape, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.bn1 = nn.BatchNorm2d(64)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = nn.Sequential(RestNetBasicBlock(64, 64, 1),
RestNetBasicBlock(64, 64, 1))
self.layer2 = nn.Sequential(RestNetDownBlock(64, 128, [2, 1]),
RestNetBasicBlock(128, 128, 1))
self.layer3 = nn.Sequential(RestNetDownBlock(128, 256, [2, 1]),
RestNetBasicBlock(256, 256, 1))
def forward(self, x):
out = self.conv1(x)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
return out.shape
class ResNet_LSTM(nn.Module):
def __init__(self, image_shape):
super(ResNet_LSTM, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.bn1 = nn.BatchNorm2d(64)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = nn.Sequential(RestNetBasicBlock(64, 64, 1),
RestNetBasicBlock(64, 64, 1))
self.layer2 = nn.Sequential(RestNetDownBlock(64, 128, [2, 1]),
RestNetBasicBlock(128, 128, 1))
self.layer3 = nn.Sequential(RestNetDownBlock(128, 256, [2, 1]),
RestNetBasicBlock(256, 256, 1))
x = torch.zeros((1, 3) + image_shape)
size = ResNet_LSTM_Shape()(x)
input_size = size[1] * size[2]
self.lstm = nn.LSTM(input_size=input_size, hidden_size=input_size, num_layers=1, bidirectional=True)
#
self.fcl = nn.Linear(input_size * 2, cate)
def forward(self, x):
out = self.conv1(x)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out) # torch.Size([2, 256, 7, 19]) [batch,layer,h,w]
out = out.permute(3, 0, 1, 2) # torch.Size([19, 2, 256, 7])
out_shape = out.shape
out = out.view(out_shape[0], out_shape[1], out_shape[2] * out_shape[3]) # torch.Size([19, 2, 1792])
out, _ = self.lstm(out) # torch.Size([19, 2, 3584])
out_shape = out.shape
out = out.view(out_shape[0] * out_shape[1], out_shape[2])
out = self.fcl(out)
out = out.view(out_shape[0], out_shape[1], -1)
return outpy
import os
import pprint
import string
from pathlib import Path
import torch
from PIL import Image
from torch.utils.data import Dataset
from tqdm import tqdm
class LetterDataset(Dataset):
def __init__(self, root: str = "./picture", transform=None):
self.path = root
self.transform = transform
self.images = self._load_picture_path()
CHAR_SET = f"_0123456789加减乘+-*"
pprint.pp({
"12": "加",
"13": "减",
"14": "+",
"15": "-",
"16": "*",
})
self.mapper = [i for i in CHAR_SET]
def _load_picture_path(self):
# 使用 lambda 表达式过滤图片文件
image_extensions = {'.jpg', '.jpeg', '.png', '.gif', '.bmp', '.tiff', '.webp'}
# 使用 os.walk 和 lambda 表达式获取所有图片路径
picture_paths = list(
map(lambda walk_result: [
[file, Path(walk_result[0]) / file]
for file in walk_result[2]
if os.path.splitext(file)[1].lower() in image_extensions
], os.walk(self.path))
)
# 将嵌套列表展平
picture_paths = [item for sublist in picture_paths for item in sublist]
return picture_paths
def __getitem__(self, index):
image = self.images[index]
image_path = image[1]
pic = Image.open(image_path)
if self.transform:
pic = self.transform(pic)
labels = [self.mapper.index(i) for i in image[0].split('_')[0]]
for i in range(9 - len(labels)):
labels.insert(0, 0)
labels = torch.as_tensor(labels, dtype=torch.int64)
return pic, labels,len(labels)
def __len__(self):
return len(self.images)
def compute_mean_std_pytorch(dataset, batch_size=8):
"""
使用PyTorch张量高效计算数据集的均值和标准差
"""
import torch
from torchvision import transforms as T # 重命名避免冲突
from tqdm import tqdm
original_transform = dataset.transform
dataset.transform = None
print("使用PyTorch方法计算...")
# 初始化统计变量
mean_accum = 0.0
sq_mean_accum = 0.0
num_pixels = 0
for i in tqdm(range(0, len(dataset), batch_size)):
batch_indices = range(i, min(i + batch_size, len(dataset)))
batch_pixels = []
for idx in batch_indices:
pic, labels, length = dataset[idx]
# 使用明确的模块引用
if isinstance(pic, Image.Image):
img_tensor = T.ToTensor()(pic) # 使用 T 而不是 transforms
else:
img_tensor = pic if torch.is_tensor(pic) else torch.tensor(pic)
batch_pixels.append(img_tensor)
if batch_pixels:
batch_tensor = torch.stack(batch_pixels)
batch_pixels_count = batch_tensor.numel()
# 累加统计量
pixel_sum = batch_tensor.sum()
pixel_sq_sum = (batch_tensor ** 2).sum()
# 更新全局统计(使用加权平均)
batch_mean = pixel_sum / batch_pixels_count
batch_sq_mean = pixel_sq_sum / batch_pixels_count
mean_accum = (num_pixels * mean_accum + batch_pixels_count * batch_mean) / (num_pixels + batch_pixels_count)
sq_mean_accum = (num_pixels * sq_mean_accum + batch_pixels_count * batch_sq_mean) / (
num_pixels + batch_pixels_count)
num_pixels += batch_pixels_count
# 计算最终标准差:sqrt(E[X²] - (E[X])²)
final_std = torch.sqrt(sq_mean_accum - mean_accum ** 2)
dataset.transform = original_transform
return [mean_accum.item()] * 3, [final_std.item()] * 3
if __name__ == '__main__':
from torchvision import transforms
transforms = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize(mean=[0.1307, ], std=[0.3081, ]),
]
)
dataset = LetterDataset(transform=transforms)
#
# # 2. 计算数据集的均值和标准差
# mean, std = compute_mean_std_pytorch(dataset, batch_size=32)
#
# # 3. 打印结果,并用于创建新的、包含标准化的数据加载流程
# print(f"计算得到的均值: {mean}")
# print(f"计算得到的标准差: {std}")py
import torch
from torch import save
from torchvision import transforms
from torch.utils.data import DataLoader
from torch import nn, optim
from tqdm import tqdm
import test
import numpy as np
from MyDataset import LetterDataset
from model_LSTM import ResNet_LSTM
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 模型
batch_size = 2
cate = 17
# 实例化模型
size = (50, 150)
model = ResNet_LSTM(size)
optimizer = optim.Adam(model.parameters())
# 加载以及训练好的模型和优化器继续训练
model = model.to(device)
loss_fn = nn.CTCLoss()
# transforms.Normalize(mean=[0.94326925, 0.94316506, 0.9447249], std=[0.19776213, 0.197599402, 0.19384143]),
transforms = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize(mean=[0.8605688810348511, 0.8605688810348511, 0.8605688810348511],
std=[0.22332395613193512, 0.22332395613193512, 0.22332395613193512]),
]
)
mine_train = LetterDataset(root='./picture/train/', transform=transforms)
def train(epoch):
total_loss = []
data_loader = DataLoader(mine_train, batch_size=batch_size, shuffle=True, drop_last=True)
data_loader = tqdm(data_loader, total=len(data_loader))
model.train()
# 三件套
for (img, label, label_length) in data_loader:
img = img.to(device)
label = label.to(device)
# 梯度置0
optimizer.zero_grad()
# 传播
output = model(img) # torch.Size([19, 2, 17])
# print(output.shape) # torch.Size([19, 2, 17])
# print(label.shape) # torch.Size([2, 9])
input_length = torch.IntTensor([output.shape[0]] * output.shape[1])
# 单次优化
loss = loss_fn(output, label, input_length, label_length)
total_loss.append(loss.item())
data_loader.set_description("loss: %.4f" % np.mean(total_loss))
# 反向传播
loss.backward()
# 优化器更新
optimizer.step()
save(model.state_dict(), './models/model.pkl')
save(optimizer.state_dict(), './models/optimizer.pkl')
loss = np.mean(total_loss)
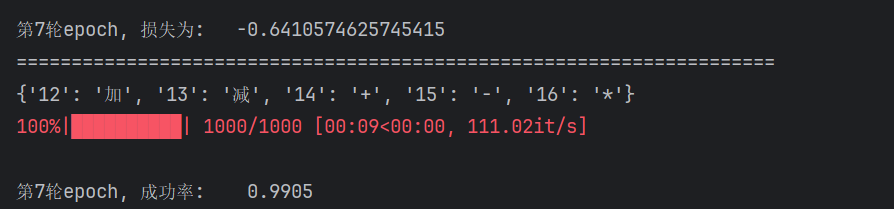
print(f"\n第{epoch}轮epoch, 损失为:\t{loss} ", )
print("=====================================================================")
for i in range(7):
epoch = i + 1
train(epoch)
print(f"\n第{epoch}轮epoch, 成功率:\t {test.test_success(i)}")py
import itertools
import os
import torch
from torch.utils.data import DataLoader
from tqdm import tqdm
from MyDataset import LetterDataset
from model_LSTM import ResNet_LSTM
batch_size = 2
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
cate = 17
def test_success(t):
total = 0
success = 0
# 实例化模型
size = (50 , 150)
model = ResNet_LSTM(image_shape=size)
model = model.to(device)
if os.path.exists('./models/model.pkl'):
model.load_state_dict(torch.load('./models/model.pkl'))
from torchvision import transforms
transforms = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize(mean=[0.8605688810348511, 0.8605688810348511, 0.8605688810348511],
std=[0.22332395613193512, 0.22332395613193512, 0.22332395613193512]),
]
)
mine_train = LetterDataset(root='./picture/test/', transform=transforms)
data_loader = DataLoader(mine_train, batch_size=batch_size, shuffle=True, drop_last=True)
data_loader = tqdm(data_loader, total=len(data_loader))
model.eval()
# 成功率列表
# 三件套
with torch.no_grad():
for (img, label, label_length) in data_loader:
img = img.to(device)
label = label.to(device)
# 获取结果
output = model(img)
output = output.permute(1, 0, 2)
for i in range(output.shape[0]):
output_result = output[i, :, :]
output_result = output_result.max(-1)[-1]
mapping = mine_train.mapper
output_s = [mapping[i[0]] for i in itertools.groupby(output_result.cpu().numpy()) if i[0] != 0]
label_s = [mapping[i] for i in label[i].cpu().numpy() if mapping[i] != '_']
if output_s == label_s:
success += 1
total += 1
return success / float(total)
# print(test_success(1))五、推理
完整代码
py
import itertools
import os
import torch
from PIL import Image
from torchvision import transforms
from model_LSTM import ResNet_LSTM
def predict_single_image(image_path='./test.png'):
"""
单张图片推理函数
Args:
image_path: 要预测的图片路径
Returns:
predicted_text: 预测的文本结果
confidence: 置信度(可选)
"""
# 设备设置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 模型初始化
size = (50, 150)
model = ResNet_LSTM(image_shape=size)
model = model.to(device)
# 加载训练好的模型权重
if os.path.exists('./models/model.pkl'):
model.load_state_dict(torch.load('./models/model.pkl', map_location=device))
# 数据预处理 - 需要与训练时保持一致[7](@ref)
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.8605688810348511, 0.8605688810348511, 0.8605688810348511],
std=[0.22332395613193512, 0.22332395613193512, 0.22332395613193512]),
])
# 设置模型为评估模式[6](@ref)
model.eval()
# 加载并预处理单张图片[1,5](@ref)
try:
image = Image.open(image_path).convert('RGB')
# 如果需要调整图片大小以匹配模型输入
# image = image.resize((150, 50)) # 根据实际情况调整
input_tensor = transform(image).unsqueeze(0) # 添加batch维度[5](@ref)
input_tensor = input_tensor.to(device)
except Exception as e:
print(f"图片加载失败: {e}")
return None
# 推理过程[6,7](@ref)
with torch.no_grad(): # 关闭梯度计算以提升效率
output = model(input_tensor)
output = output.permute(1, 0, 2) # 调整维度顺序
# 解码预测结果[2](@ref)
# 创建mapper实例(需要根据您的实际mapper实现调整)
from MyDataset import LetterDataset
mine_train = LetterDataset(root='./picture/test/', transform=transform)
mapping = mine_train.mapper
predicted_texts = []
for i in range(output.shape[0]):
output_result = output[i, :, :]
output_result = output_result.max(-1)[-1] # 获取最大概率的索引
# 使用groupby合并连续重复的字符,并过滤掉空白符[2](@ref)
output_s = [mapping[i[0]] for i in itertools.groupby(output_result.cpu().numpy()) if i[0] != 0]
predicted_text = ''.join(output_s)
predicted_texts.append(predicted_text)
# 返回第一个预测结果(如果是单张图片,通常只有一个结果)
return predicted_texts[0] if predicted_texts else ""
# 使用示例
if __name__ == "__main__":
result = predict_single_image('./424+123_1767498617376_0.png')
# result = predict_single_image('./test.png')
print(f"预测结果: {result}")成功率
六、计算验证码
py
import re
from typing import Union
class CaptchaCalculator:
"""数学验证码计算器类"""
def __init__(self):
self.operator_map = {
'加': '+', '减': '-', '乘': '*',
'+': '+', '-': '-', '*': '*',
'×': '*', '÷': '/'
}
def calculate(self, expression: str) -> int:
"""
计算数学表达式验证码
Args:
expression: 包含数学表达式的字符串
Returns:
int: 计算结果
"""
if not expression or not isinstance(expression, str):
raise ValueError("表达式不能为空且必须是字符串")
try:
# 清理和标准化表达式
cleaned_expr = self._clean_expression(expression)
# 提取数学表达式
math_expr = self._extract_math_expression(cleaned_expr)
# 安全计算表达式
return self._evaluate_expression(math_expr)
except Exception as e:
raise ValueError(f"计算表达式 '{expression}' 时出错: {str(e)}")
def _clean_expression(self, expression: str) -> str:
"""清理表达式,标准化运算符和格式"""
# 替换中文运算符为英文运算符
for chinese_op, english_op in self.operator_map.items():
expression = expression.replace(chinese_op, english_op)
# 移除空格
expression = expression.replace(' ', '')
return expression
def _extract_math_expression(self, text: str) -> str:
"""从文本中提取数学表达式"""
# 更灵活的模式匹配,支持各种格式
patterns = [
r'(\d+)\s*([+*/-])\s*(\d+)', # 数字 运算符 数字
r'([+-]?\d+)\s*([+*/-])\s*([+-]?\d+)', # 可能带符号的数字
]
for pattern in patterns:
match = re.search(pattern, text)
if match:
num1, operator, num2 = match.groups()
return f"{num1}{operator}{num2}"
# 如果没有匹配到标准模式,尝试提取所有数字和运算符
numbers = re.findall(r'[+-]?\d+', text)
operators = re.findall(r'[+*/-]', text)
if len(numbers) >= 2 and len(operators) >= 1:
return f"{numbers[0]}{operators[0]}{numbers[1]}"
raise ValueError(f"无法从文本中提取有效的数学表达式: {text}")
def _evaluate_expression(self, expression: str) -> int:
"""安全地计算数学表达式"""
# 验证表达式安全性
if not self._is_safe_expression(expression):
raise ValueError("表达式包含不安全字符")
# 使用更精确的解析方法
pattern = r'([+-]?\d+)\s*([+*/-])\s*([+-]?\d+)'
match = re.match(pattern, expression)
if not match:
raise ValueError(f"表达式格式错误: {expression}")
num1_str, operator, num2_str = match.groups()
try:
num1 = int(num1_str)
num2 = int(num2_str)
except ValueError:
raise ValueError("数字格式错误")
# 根据运算符计算结果
if operator == '+':
result = num1 + num2
elif operator == '-':
# 修改:直接返回减法结果,不取绝对值
result = num1 - num2
elif operator == '*':
result = num1 * num2
elif operator == '/':
if num2 == 0:
raise ValueError("除法运算中除数不能为零")
result = num1 / num2
# 对于除法,返回整数结果
result = int(result)
else:
raise ValueError(f"不支持的运算符: {operator}")
return int(result)
def _is_safe_expression(self, expression: str) -> bool:
"""检查表达式是否只包含安全字符"""
# 修复正则表达式中的字符范围问题
safe_pattern = r'^[0-9+*/\-.\s()]+$'
return bool(re.match(safe_pattern, expression))
def batch_calculate(self, expressions: list) -> dict:
"""批量计算多个表达式"""
results = {
'successful': {},
'failed': {}
}
for expr in expressions:
try:
result = self.calculate(expr)
results['successful'][expr] = result
except Exception as e:
results['failed'][expr] = str(e)
return results七、请求数据
识别验证码
py
def predict_single_image(image_path='./test.png'):
"""
单张图片推理函数
Args:
image_path: 要预测的图片路径
Returns:
predicted_text: 预测的文本结果
confidence: 置信度(可选)
"""
# 设备设置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 模型初始化
size = (50, 150)
model = ResNet_LSTM(image_shape=size)
model = model.to(device)
# 加载训练好的模型权重
if os.path.exists('models/model.pkl'):
model.load_state_dict(torch.load('models/model.pkl', map_location=device))
# 数据预处理 - 需要与训练时保持一致[7](@ref)
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.8605688810348511, 0.8605688810348511, 0.8605688810348511],
std=[0.22332395613193512, 0.22332395613193512, 0.22332395613193512]),
])
# 设置模型为评估模式[6](@ref)
model.eval()
# 加载并预处理单张图片[1,5](@ref)
try:
image = Image.open(image_path).convert('RGB')
# 如果需要调整图片大小以匹配模型输入
# image = image.resize((150, 50)) # 根据实际情况调整
input_tensor = transform(image).unsqueeze(0) # 添加batch维度[5](@ref)
input_tensor = input_tensor.to(device)
except Exception as e:
print(f"图片加载失败: {e}")
return None
# 推理过程[6,7](@ref)
with torch.no_grad(): # 关闭梯度计算以提升效率
output = model(input_tensor)
output = output.permute(1, 0, 2) # 调整维度顺序
# 解码预测结果[2](@ref)
# 创建mapper实例(需要根据您的实际mapper实现调整)
from MyDataset import LetterDataset
mine_train = LetterDataset(root='./picture/test/', transform=transform)
mapping = mine_train.mapper
predicted_texts = []
for i in range(output.shape[0]):
output_result = output[i, :, :]
output_result = output_result.max(-1)[-1] # 获取最大概率的索引
# 使用groupby合并连续重复的字符,并过滤掉空白符[2](@ref)
output_s = [mapping[i[0]] for i in itertools.groupby(output_result.cpu().numpy()) if i[0] != 0]
predicted_text = ''.join(output_s)
predicted_texts.append(predicted_text)
# 返回第一个预测结果(如果是单张图片,通常只有一个结果)
return predicted_texts[0] if predicted_texts else ""获取验证码
py
def get_captcha_success(path):
# 实例化模型
img_url = "https://www.python-spider.com/api/challenge18/verify"
# 添加浏览器头信息
headers = {
"accept": "image/avif,image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8",
"accept-language": "zh-CN,zh;q=0.9",
"cache-control": "no-cache",
"pragma": "no-cache",
"priority": "i",
"referer": "https://www.python-spider.com/challenge/18",
"sec-ch-ua": "\"Google Chrome\";v=\"143\", \"Chromium\";v=\"143\", \"Not A(Brand\";v=\"24\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "image",
"sec-fetch-mode": "no-cors",
"sec-fetch-site": "same-origin",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36"
}
cookies = {
"__jsl_clearance": "1767260178.981|0|clD4VpfqhdaLBWywKWy%2FZyfi6d_c320c9b626e7de36088d38e2b53ad6a33D"
}
params = {
"0.9360506012595505": ""
}
# 发送GET请求获取图片[5,6](@ref)
response = session.get(img_url, headers=headers, params=params, cookies=cookies, stream=True)
response.raise_for_status() # 检查请求是否成功
with open(path, 'wb') as f:
f.write(response.content)
f.close()
# img = Image.open("./test.png")
captcha = predict_single_image(path)
return captcha循环100次拿页面数据
py
if __name__ == '__main__':
tot = 0
count = 100
while count > 0:
headers = {
"accept": "application/json, text/javascript, */*; q=0.01",
"accept-language": "zh-CN,zh;q=0.9",
"cache-control": "no-cache",
"content-type": "application/x-www-form-urlencoded; charset=UTF-8",
"origin": "https://www.python-spider.com",
"pragma": "no-cache",
"priority": "u=1, i",
"referer": "https://www.python-spider.com/challenge/18",
"sec-ch-ua": "\"Google Chrome\";v=\"143\", \"Chromium\";v=\"143\", \"Not A(Brand\";v=\"24\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36",
"x-requested-with": "XMLHttpRequest"
}
cookies = {
"__jsl_clearance": "1767260178.981|0|clD4VpfqhdaLBWywKWy%2FZyfi6d_c320c9b626e7de36088d38e2b53ad6a33D"
}
url = "https://www.python-spider.com/api/challenge18"
captcha_expression = get_captcha_success('./test.png')
captcha_calculator = CaptchaCalculator()
captcha_input = captcha_calculator.calculate(captcha_expression)
print(f"表达式: {captcha_expression}, 计算结果: {captcha_input}")
data = {
"page": count,
"code": captcha_input
}
# data = json.dumps(data, separators=(',', ':'))
response = session.post(url, headers=headers, cookies=cookies, data=data, verify=False)
print(response.status_code)
print("=" * 50)
if response.status_code != 200:
print(f"❌ 正在爬取 第{count}页, 爬去失败")
continue
response = response.json()
if response.get('state') == 'success' and response.get('data'):
page_data = response['data']
print(page_data)
# 方法1:使用列表推导式统一转换为整数
numbers_int = [int(x['value']) for x in page_data]
# 然后使用sum函数求和
total = sum(numbers_int)
print(f"✅ 正在爬取 第{count}页, 本页总和: {total}\n数据为:{numbers_int}")
tot = tot + total
count = count - 1
else:
print(f"❌ 正在爬取 第{count}页, 爬去失败")
continue
exit()
print("总计:", tot)完结撒花 🎉🎉🎉